
 August 20th, 2006
August 20th, 2006
The reporter is the part of Newman which retrieves stories from various websites. The process is fairly straightforward:
- Retrieve web page containing a list of the latest news stories.
- Read the list of stories and retrieve links to individual stories.
- Retrieve each story one by one.
This description is generic enough to be satisfied by every site of those I considered reporting from, notably Football Italia, Tribalfootball, Eurosport, and Goal. Every site has a list of stories and then individual stories on separate pages. But that doesn't mean there weren't a few challenges to make this work, notably:
- Every site uses different html - we have to read the info we need out of the html source by using regular expressions.
- The result from every story retrieval should be just plain text, no html tags or other code.
- If the connection fails or times out, Newman should ignore the error and continue, it shouldn't crash.
Out of every story we need the title, the date, and the body of the story. The rest we can blissfully ignore. But evenso, Football Italia presents these three elements in the order we want, but Goal prints the date first, then the title and body. It also divides the body into a summary and the rest. So these trivial variations had to be handled specifically for each site. Doing this requires analysis of the html code, which is not something Newman can do automatically. The image below shows a sample of html source and below it the regular expression needed to parse it.
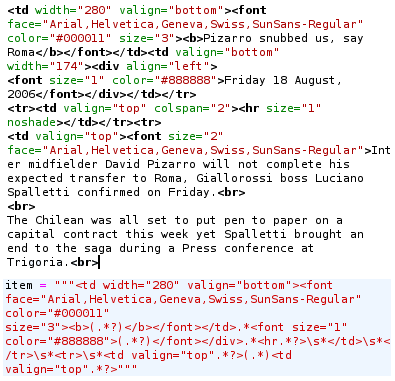
One other point is that this parsing (text analysis) depends on the html being a certain way, everytime. So if one story has two <br> tags between the date and the body, but another story has three, the parsing is likely to fail (the parsing is in fact a bit smarter than that, but it will only work with small variations). Even worse, should one of these sites do a redesign and change their whole html code, the whole analysis would have to be redone (this took me anything from 5 to 30 minutes for every site).
Once the three elements of the story have been read, it all has to be cleaned up and formatted. We don't want any html tags anywhere, and we don't want any funny characters that will come out garbled. Anything retrieved from the web is by definition garbage, so we need to make sure that we clean it up whether or not it is clean. Once we've done that, we need to do some formatting. Again we assume nothing about how the story is formatted when it comes in. For all we know there may be 14 spaces between each word (html ignores whitespaces when there is more than one), 5 line breaks between paragraphs and so on. There are some things we can fix easily - for instance there should never be a space between a character and a comma that follows it - and some things we cannot do much about - it is difficult to determine whether there is a line break within a sentence, because it's hard to tell what is a sentence and what isn't (do sentences always begin with a capital letter? what if there is a typo in the story? or what if a name is capitalized, how do you know if that's the start of the sentence or just a part of it? what if the previous sentence is missing a full stop? etc).
Ultimately, Newman is quite good at reporting stories. It tolerates connection errors and it has a very high success rate in cleaning and formatting stories correctly. It does sometimes miss funky special characters on account of web sites not telling us what character set they use (or saying they use one but then encoding in another one, or differences in encoding from one story to the next etc).
One last important issue the reporter does for us is handle the story cache. When the list of stories is retrieved, Newman stores the story title and url to the story in a cache, so that next time it again retrieves the list of stories, it will know which stories it has already retrieved in the past (to make sure the same story won't be posted multiple times). This reduces the amount of bandwidth that Newman uses (let's be nice to web hosts) and it speeds up Newman as well.
This entry is part of the series Project Newman.
