
 October 12th, 2013
October 12th, 2013
So, writing an interpreter. Where do we even start?
Why, with the essentials. While an interpreter is nothing more than a program that reads your program and runs it, that is a pretty complicated undertaking. You could conceivably write an interpreter that reads a program character by character and tries to execute it, but you would soon run into all kinds of problems, like: I need to know the value of this variable, but that's defined somewhere else in the program, and: I'm executing a function definition, which doesn't have any effect, but I need to remember that I've seen it in case anyone is calling the function later in the program.
In fact, this approach is not wrong, it's basically what your machine really does. But your machine is running machine code, and you're not, and therein lies the difference. People don't write programs in machine code anymore. It's too hard. We have high level languages that provide niceties like variables - define once, reference as often as you like. Like functions. Like modules. All of these abstractions amount to a program that is not a linear sequence of instructions, but a network of blocks of instruction sequences and various language specific structures like functions and classes that reference each other.
And yet, since many languages are compiled down to machine code, there must be a way to get from here to there? Well, compiler writers have decided that doing so in one step is needlessly complicated. And instead we do what we always do in software engineering when the problem is too hard: we split it into pieces. A compiler will run in multiple phases and break down the molecule into ever simpler compounds until it's completely flat and in the end you can execute it sequentially.
Interpreters start out the same way, but the goal is not machine code, it's execution of the program. So they bottom out in an analogous language to machine code: byte code. Byte code can be executed sequentially given a virtual machine (language specific) that runs on top of a physical machine (language agnostic) that knows a few extra things about the language it's running.
Phases
Parsing - Read the program text and build a structured representation (abstract syntax tree) out of it.
Compilation - Compile the AST to bytecode instructions that can be executed on a stack machine.
Interpretation - Pretend to be a machine and execute the bytecode.
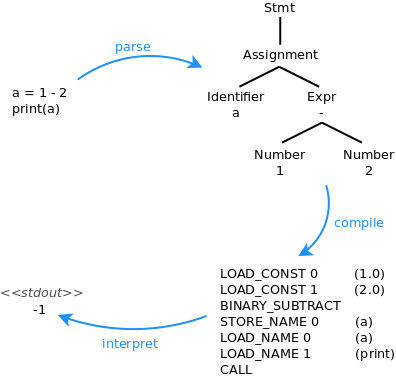
The parser is the thing that will read the program text, but it needs to know the syntax of the programming language to recognize what it's reading. This is supplied in the form of a grammar. The parser also needs to know the structure of your abstract syntax for it to build those trees for you. And this is where it gets tricky, because the AST is one of the central data structures in an interpreter, and the way you design the AST will have a big impact on how awkward or convenient it will be to do anything meaningful with it. Even so, the AST much match the grammar very closely, otherwise it's going to be very hard to write that parser. So the optimal would be to design the AST first, then write a grammar that matches it to the letter (even better: you could generate the grammar from the AST). Well, there are decades of research that explain why this is hard. Long story short: the more powerful the parser the more leeway you have in the grammar and the easier it is to get the AST you want. Chances are you will not write the parser from scratch, you'll use a library.
The compiler is the thing that traverses an AST and spits out bytecode. It's constrained by two things: the structure of the AST, and the architecture of the vm (including the opcodes that make up your bytecode). Compilers really aren't generic - they need to know all the specifics of the machine they are compiling for. For virtual machines this means: is it a stack machine or a register machine? What are the opcodes? How does the vm supply constants and names at interpretation time? How does it implement scope and modules?
Finally, the interpreter is the thing that emulates a machine and executes the bytecode. It will read the bytecode sequentially and know what to do with each instruction. It's really the only part of the entire program that interacts with its environment extensively. It's the thing that produces output, opens sockets, creates file descriptors, executes processes etc, all on behalf of your program. In fact, it would be more correct to say that these things are contained in the standard libraries of the language, but the interpreter is what orders them to happen.
luna 0.0.1
It's out. An interpreter for basic blocks. All your code runs in a single stack frame, so you can only run expressions, assignments and function calls. There is an object model for lua values. There is a pretty barebones standard library. And there are tests (py.test is making life quite good so far).